跳转至内容
严谨求实-孔庆钊课题组
同济大学-土木工程学院-结构防灾减灾工程系
数字孪生
物联网监测运维系统
陆家嘴区域El-Centro地震波响应
大坝施工期运维系统
大坝抗震防灾分析预警系统
柔性管道数字孪生监测系统
水陆空无人装备集群实时数字孪生系统
流式数据有限元实时计算引擎
结构抗震分析与写实渲染系统
动力求解器与非线性动力求解器
数字同济
人工智能
三维损伤量化
建筑物三维实时重建APP
复杂环境下的语义理解
施工人员安全监控
建筑物三维实时理解APP
叩诊法螺栓松紧度检测
无人机螺栓松动检测
边坡隐患解算
云原生架构的图像修复网络耦合目标感知
基于对抗生成网络的钢筋混凝土梁损伤分析与量化
2D全景解算3D室内空间
硬件装备
外立面检测机器人
物联网气象站
实时三维重建机器人
DIMS-DT-001型边云协同计算单元
DIMS-DT-002型边云协同计算单元
激光点云实时室内灾情重构机器人
灾情下大尺度城市集群无人机建筑倾角快速评估
无人机隧道电路过载检测
扩展现实
MR陆家嘴区域虚拟底座
MR混合现实结构透视
AR增强现实的BIM
搜索:
数字孪生
物联网监测运维系统
陆家嘴区域El-Centro地震波响应
大坝施工期运维系统
大坝抗震防灾分析预警系统
柔性管道数字孪生监测系统
水陆空无人装备集群实时数字孪生系统
流式数据有限元实时计算引擎
结构抗震分析与写实渲染系统
动力求解器与非线性动力求解器
数字同济
人工智能
三维损伤量化
建筑物三维实时重建APP
复杂环境下的语义理解
施工人员安全监控
建筑物三维实时理解APP
叩诊法螺栓松紧度检测
无人机螺栓松动检测
边坡隐患解算
云原生架构的图像修复网络耦合目标感知
基于对抗生成网络的钢筋混凝土梁损伤分析与量化
2D全景解算3D室内空间
硬件装备
外立面检测机器人
物联网气象站
实时三维重建机器人
DIMS-DT-001型边云协同计算单元
DIMS-DT-002型边云协同计算单元
激光点云实时室内灾情重构机器人
灾情下大尺度城市集群无人机建筑倾角快速评估
无人机隧道电路过载检测
扩展现实
MR陆家嘴区域虚拟底座
MR混合现实结构透视
AR增强现实的BIM
复杂环境下的语义理解
核心价值
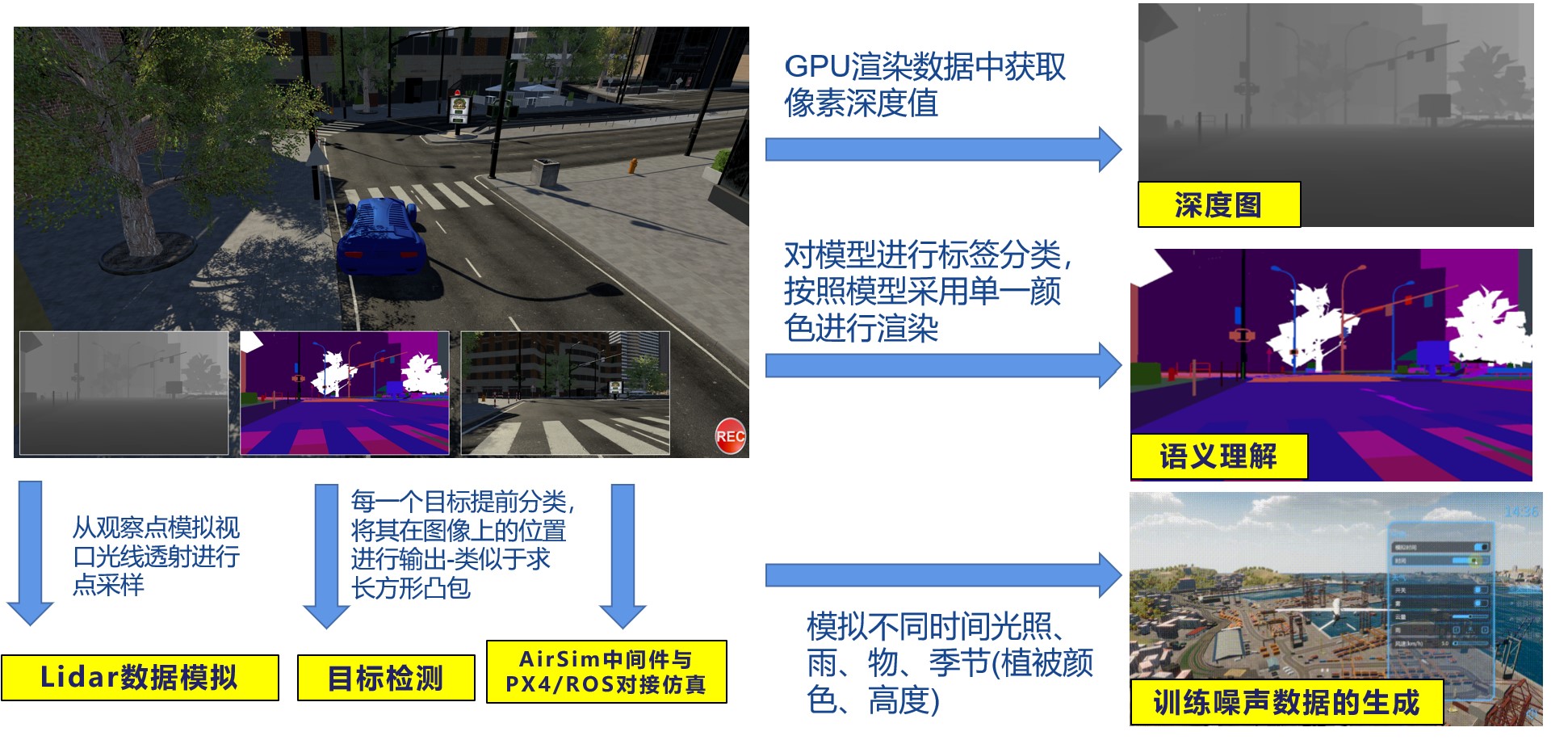
通过搭建具有深度信息及语义分割信息的场景融合逼真的实时/离线光追渲染技术训练视觉语义理解模型,服务于机器人自主避障、自动驾驶场景理解、无人机自主飞行等应用。该研究为未来灾情结构损伤检测机器人自主性提供研究基础。
研究成果呈现形式
场景语义理解训练平台
在线训练平台场景细节复原
Previous
Next
虚拟训练平台数据层
虚拟实景训练平台
场景理解模型实测
实时拍摄影像(带识别与追踪)
场景实时理解
返回页首